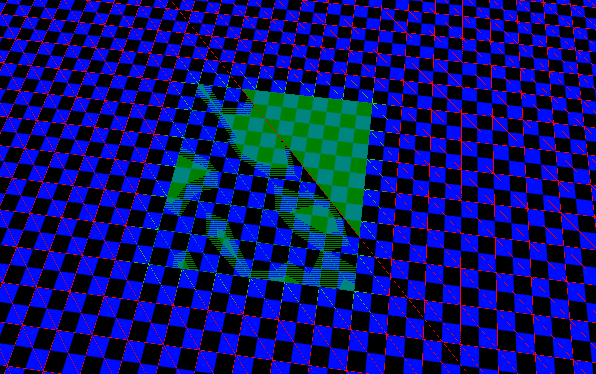
I’ve been working on rendering a square terrain heightmap that I can manipulate in realtime, and my current setup works for anything around 129129 vertices. But when I try 257257 vertices, I see some strange artifacts; the wireframe doesn’t appear correct and backface culling seems to fail. A second, flat “ghost” grid appears overlayed with the main one, and won’t respond to my manipulations. When I try 513*513 vertices, the grid doesn’t render at all, but the program is still slowed down as if vertex processing and everything is being done.
I substituted simpler vertex and fragment shaders to see if the problem was there. The FPS jumped up and camera movement was as smooth as it was at lower heightmap resolutions, but the visual problems remained, so I concluded the main problem wasn’t in the shaders.
Then I thought the problem might be in the number of vertices on screen (I was only doing backface culling). So I implemented a simple space partitioning system that broke the grid evenly into 33x33 squares and did some frustum culling so only those in the viewing frustum would be rendered (by binding a unique IBO per chunk). I’m certain the code’s correct, since I reused it from an older project that worked fine. The visual artifacts still remained, so I concluded the problem wasn’t with the number of triangles I’m attempting to draw.
Now I’m considering whether the issue might be the size of the single VBO I’m using. I’m not sure how much a single VBO can hold, and how much my integrated graphics card can hold, total.
Each vertex is 60 bytes. 257x257 of them means nearly 4GB of data. That seems a lot; is it actually? If this is the case, breaking my grid up into squares with their own IBOs won’t help much since they index into the same giant buffer. Having a separate VBO per chunk won’t help either because they’ll all be loaded anyway.
If the amount of data on the card is the problem, the only way I can think of around it would be to have an array of vertices CPU-side, and then build a separate VBO per chunk. Then I’d need to store all the data CPU-side and call glBufferData when I want to draw a specific chunk, which seems really wasteful and beats the point of modern OpenGL programming. But it’s the only thing I can think of; if there’s too much data on the graphics card I need to make sure there’s less on it at any given moment.
Is there any other, less wasteful way to reduce the memory load on the graphics card?
Edit - ignore the GL_MAX_ELEMENTS_VERTICES in the title. I put that there since it was returning 1200, which I thought might be the problem, but then I read a bit more and realized it only referred to glDrawRangeElements and didn’t mean much anymore. Unfortunately I can’t find any way to edit the title.