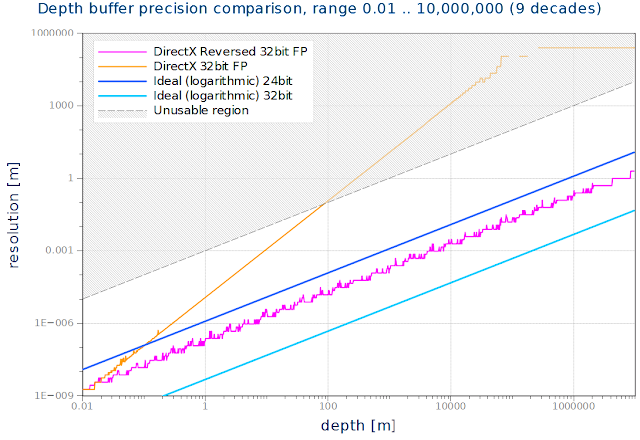
So I try to get the luxury of a decent depth buffer resolution but so far only see the horrors of z fighting.
Here is what I “understand”:
First I need GL_NV_depth_buffer_float with glDepthRangedNV(-1.0, 1.0)
or
GL_ARB_clip_control with glClipControl(GL_LOWER_LEFT, GL_ZERO_TO_ONE)
(As I understand it, the glDepthRange in core gl >= 4.3 is still clamped and therefor still useless for this?)
Then I use a FBO with a depth buffer of the type GL_DEPTH_COMPONENT32F
And now I also have to use a inverted projection matrix so that 0 becomes the far plane.
Including using clearDepth(1.0f) and glDepthFunc(GL_GREATER);
I tried scale with (1.0f, 1.0f, -1.0f) or invert the near and far values and a bunch of other stuff. But I never got any more precision out of it.
The only thing I noticed is, that I get more precision (like 1 bit?) when I use glClipControl(GL_LOWER_LEFT, GL_ZERO_TO_ONE) in all cases, even when not using a float depth buffer.
This makes me believe that my assumption that glClipControl(GL_LOWER_LEFT, GL_ZERO_TO_ONE) does the same as glDepthRangedNV(-1.0, 1.0) are totally wrong.
For testing I use 2 simple planes with width 10, depth 1000, and a height difference of 0.1
With a zNear, zFar value of 0.01, 100000.0 I get a lot of z-fighting even before 1000.0, with everything I tried so far.