Hello everyone,
I am a little confused about the conditions for early fragment rejection based on depth.
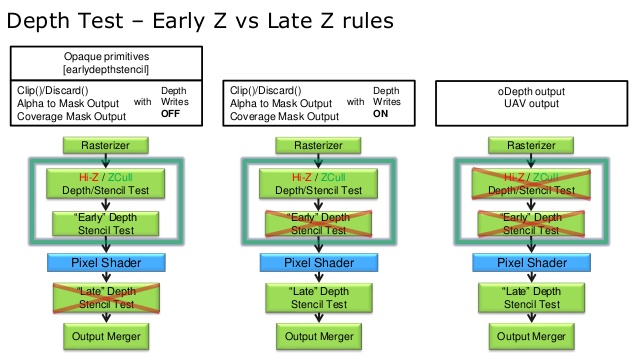
I read that in most drivers early depth tests (between vs and fs) are only used if:
-no alpha to sample coverage
-no discard in fs
-no changes to z position
While the last condition (no z position changes) is quite obvious, I am not so sure about the reasoning for the other two.
In my mind early rejection should be fine either way, as long as the depth buffer is only written after the fragment shader runs.
I could only come up with two possible explanations:
- Something similar to imageAtomicMin is used on the depth buffer only once, which somehow mitigates the impact of the in-order-rasterization guarantee.
- The memory bandwith used by having both a z-test during rasterization and after the fs is too high.
In case 1 it would be interesting if there are proposals for disabling this guarantee (amd offers this for vulkan).
I have my doubts about case 2 because that sounds like a small memory bandwidth cost given the chance to reduce the number of fragment shader executions.
Does anyone know more details on what is actually going on?